Der Umgang mit fehlenden Werten („Missing Values“) in Daten ist zentral für die Auswertung. Manche fehlende Werte möchte man in Auswertungen sehen, andere jedoch nicht. Manche fehlende Werte sollen in der Berechnung von Anteilen berücksichtigt werden, andere sollen ausgeschlossen werden.
In DataLion ist ein umfangreiches Handling von fehlenden Werten vorgesehen. Fehlende Werte sowie deren Ein- und Ausschluss bei Berechnungen können auf Projekt (im Backend)- und Fragenebene (im Codebook; s.u.) definiert werden.
Wichtig: Bei der Definition von Missings im Backend und im Codebook hat die Einstellung im Codebook Vorrang.
Im Backend können folgende Einstellungen standardmäßig für ein komplettes Projekt definiert werden:
- Werte, die als fehlende Werte behandelt werden sollen (nutzerdefinierte Werte sowie NULL und Leere Zeichenketten)
- Umgang mit fehlenden Werten (sollen diese standardmäßig in die Gesamtzahlbestimmung für eine Berechnung eingehen oder diese Werte für Berechnungen ignoriert werden)
Beispiel: wird “99” als fehlender Wert definiert und diese in Berechnungen ignoriert, so …
- werden alle Einträge mit “99” für die Berechnung einer Summe oder eines Mittelwerts nicht berücksichtigt.
- wird bei der Bestimmung von Prozentwerten ausschließlich auf die Werte prozentuiert, die keine “99” sind.
Anwendungsfall:
Ein typischer Anwendungsfall, in dem fehlende Werte in die Berechnung von Summen/Mittelwerten oder Prozentwerten einfließen sollen (oder auch nicht) ist bei Filterfragen in Fragebögen.
Beispiel: Die Zufriedenheit mit einem Produkt wird nur von Personen bewertet, die zuvor angegeben haben, das Produkt zu kennen. Diejenigen, die angegeben haben das Produkt nicht zu kennen, haben bei der Frage nach der Zufriedenheit fehlende Werte
- Nun kann es interessant sein zu erfahren, wie zufrieden diejenigen Personen sind, die das Produkt kennen (Zufriedenheit ausschließlich derer, die das Produkt kennen → fehlende Werte werden nicht berücksichtigt)
- Oder zu erfahren, wie viele aller befragten Personen mit dem Produkt zufrieden sind (Zufriedenheit derer, die das Produkt kennen, allerdings im Verhältnis zu allen befragten Personen → fehlende Werte müssen in der Prozentuierung berücksichtigt werden)
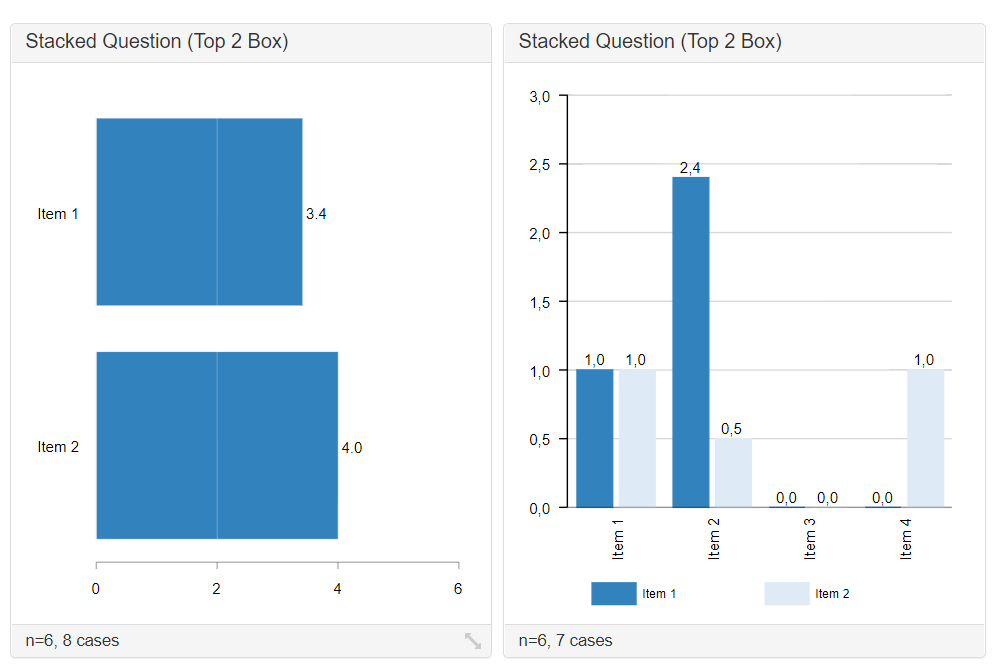
Illustration (Mittelwerte):
- Fehlende Werte bei Q1: 0 → wird 0 in die Berechnung einbezogen, so ist der Mittelwert nach unten verzerrt und die Fallzahl höher)
- Fehlende Werte bei Q2: 99 → wird 99 (fälschlicherweise) in die Berechnung einbezogen, so ist der Mittelwert nach oben verzerrt und die Fallzahl größer)

Illustration (Prozente):
- Fehlende Werte bei Q2: 99 → wird 99 aus der Berechnung für die Prozentwerte ausgeschlossen, so ist die Fallzahl niedriger (nur diejenigen, die ein Produkt kennen) und der Prozentwert höher.
Wird 99 für die Berechnung der Prozente berücksichtigt, so wird die Fallzahl höher (alle befragten Personen) und der Prozentwert niedriger.
Einstellungen im Codebook
Im Codebook können in der Spalte „Settings“ die folgenden Optionen fragenspezifisch in geschwungenen Klammern ergänzt werden (Achtung: überschreibt Projkekteinstellungen):
- Fehlende Werte vom Projekt abweichend definieren:
{„na“: „fehlenderWert1“} bzw. {„na“: „fehlenderWert1“, „fehlenderWert2“, „etc.“} - Fehlende Werte ausschließen: {„exclude_na“:true}
→ als fehlend definierte Werte werden für die Bestimmung von Prozentwerten nicht in der Gesamtzahl berücksichtigt - Fehlende Werte einschließen: {„exclude_na“:false}
→ als fehlend definierte Werte werden für die Bestimmung von Prozentwerten in der Gesamtzahl berücksichtigt
Mehrere Einstellungen können durch Komma getrennt verbunden werden, z.b.
{„na“: „fehlenderWert1„, „exclude_na“:false}